
La conception d’algorithmes robustes d’IA et applications aux d’usage industriels de Confiance.ai
Dans notre article « 8 défis scientifiques sur l’approche globale pour des composants d’IA à confiance maitrisée« , nous avons énuméré un certain nombre de défis scientifiques identifiés par le programme Confiance.ai. Cet article sera consacré au défi « Construire des composants IA à confiance maîtrisée » et la sous-catégorie « Garantir et mesurer la robustesse ». Nous y discuterons de la performance dans le contexte de la robustesse et, face à des perturbations ou des attaques adverses.
La robustesse est un élément clé de la fiabilité des systèmes à base d’IA, tout comme l’explicabilité, l’interprétabilité, la fairness, etc. Celle-ci peut être définie au niveau global (capacité du système à remplir la fonction prévue en présence d’entrées anormales ou inconnues) ou au niveau local (la mesure dans laquelle le système fournit des réponses équivalentes pour des entrées similaires). Tout au long du programme Confiance.ai, diverses méthodes pour la conception robuste des algorithmes IA ont été identifiées et leurs apports aux cas d’usage industriels ont été évalués. Voici quelques-unes de ces méthodes.
Le lissage aléatoire ou le Randomised smoothing (RS)
Le Randomised smoothing (RS) est une technique ayant des garanties théoriques de robustesse locale. Cette méthode consiste à prendre une décision moyenne pour plusieurs entrées perturbées de la même source. Considérons le cas d’usage de Renault de classification d’images de soudures en bonne ou mauvaise soudure :

Figure 1 : Classification des soudures (cas d’usage Renault)
La figure qui suit montre la performance face à des attaques adverses de plusieurs modèles de classification de soudure: un réseau développé par Renault (SVM NN) ainsi que 5 autres modèles RS entrainés pour différentes typologies de bruit. Si deux des modèles (vanilla laplace 0.1 et vanilla uniform 0.1 courbe verte et courbe bleue) ont des résultats moins bons que le modèle de Renault, les trois autres sont parfaitement robustes (leurs trois tracés se superposent à l’ordonnée 100%).
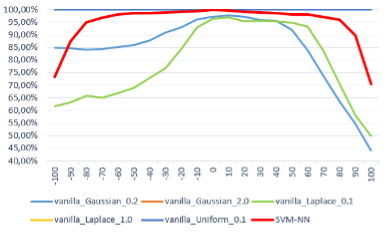
Figure 2 : Comparaison de la sensibilité de différents modèles à la variation de la perturbation
Le RS donne ainsi des résultats très satisfaisants mais au prix d’un apprentissage plus lourd et aussi d’une inférence plus coûteuse.
Au-delà de la classification, nous avons aussi expérimenté le RS pour les problématiques de régression afin de répondre à un cas d’usage d’Air Liquide. Celui-ci consiste à prédire la demande de gaz par la clientèle Air Liquide. Dans ce cas, le RS permet de donner des intervalles certifiés pour la prévision de la demande et donc une meilleure visibilité et gestion de la demande.

Figure 3 : La courbe en noir montre la vraie demande par la clientèle d’Air Liquide, les autres courbes montrent des prédictions par le RS pour différentes typologies de bruit. La zone en bleu est la zone de certification par le RS : celle-ci est censé contenir les vraies valeurs (la courbe en noir) avec une forte probabilité.
L’entraînement adverse ou Adversarial training
Cette approche consiste à injecter durant l’apprentissage des exemples adverses souvent générés par des attaques de l’état de l’art comme PGD ou Auto-PGD. Le modèle obtenu en conséquence sera cependant résilient face à tout type d’attaque ou perturbation. L’entrainement adverse permet certainement d’améliorer la robustesse mais induit forcément une baisse de la précision par rapport à un entrainement classique (no-free lunch !). Plusieurs variantes de cette méthode ont été utilisées dans Confiance.ai comme TRADES essayant de maximiser un compromis entre à la fois robustesse et précision.
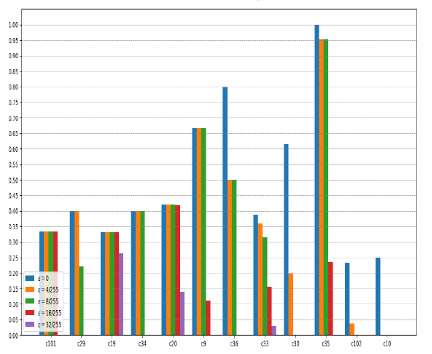
Figure 4 : Comparaison des performances entre 12 modèles de réseau de neurones entrainés avec la méthode TRADES face à des attaques adverses d’intensité ɛ pour plusieurs valeurs de ɛ. C101, C29 etc désignent différents datasets d’entrainement selon plusieurs angles de vue.
Les réseaux Lipschitz
La plupart des réseaux de neurones sont Lipschitz mais le calcul de la constante Lipschitz est généralement difficile (NP difficile). Les réseaux Lipschitz ont des constantes de Lipschitz calculables par conception. Ces modèles sont donc localement robustes. Les performances des réseaux Lipschitz ont été évaluées pour divers cas d’usage du programme Confiance.ai comme par exemple : ACAS-Xu d’Airbus.
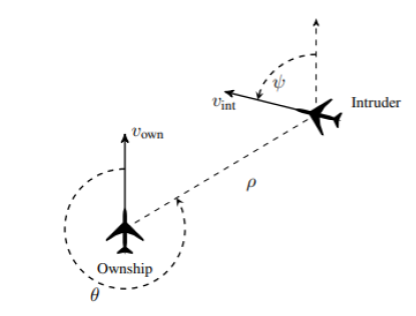
Figure 5 : Le système anticollision embarqué ACAS-Xu utilise la programmation dynamique afin d’éviter les collisions d’avions. Cinq actions sont possibles à chaque instant (Clear-of-Conflict; Weak Left; Weak Right; SL: Strong Left; Strong Right). Un système à base d’IA doit choisir une action optimale parmi ces 5 actions.
Sur la figure suivante, on peut visualiser les scores de certification de trois modèles réseaux de neurones Lipschitz entrainés avec différents hyper-paramètres d’apprentissage. Les modèles les plus robustes sont ceux ayant les scores de certification les plus élevés. Le meilleur modèle obtenu est donc celui à droite.
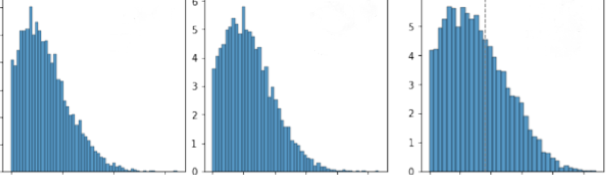
Figure 6 : Scores de certification pour trois modèle réseaux Lipschitz entrainés sur le cas d’usage Acas-Xu.
Références :
- Livrable Confiance.ai Robust & Embeddable Deep Learning by Design
- Rendre une IA robuste au bruit : ActuIA 2022, Rodolphe Gelin, Augustin Lemesle, Hatem Hajri