
L’explicabilité et l’interprétabilité : deux notions intrinsèques pour la transparence des systèmes d’IA
Au sein du programme Confiance.ai, l’explicabilité se définit par la capacité d’un système d’intelligence artificielle (IA) à exprimer des facteurs importants influençant ses résultats d’une manière compréhensible par les humains. Au vu de sa définition, l’explicabilité est utile à la transparence des systèmes de décision basés sur de l’IA, notion essentielle pour la bonne acceptation de l’IA par les parties prenantes comme l’utilisateur final, le concepteur, l’autorité de certification de l’IA ou encore l’autorité d’enquête en cas d’accident.
Aujourd’hui, on ne peut pas parler d’explicabilité sans évoquer l’interprétabilité qui se définit par la capacité de représentation d’un élément d’un système d’IA à être associée à un modèle mental humain. Ainsi, l’explicabilité s’attache à une propriété intrinsèque du système d’IA lorsque l’interprétabilité s’attache à la représentation que se fait un utilisateur d’un élément de ce système. Là où il peut y avoir confusion, c’est lorsqu’il est indiqué que l’interprétabilité est un préalable à l’explication. Il y a alors deux lectures à cela :
- L’interprétabilité du système d’IA conduit à son explicabilité ;
- L’interprétabilité appliquée aux résultats d’explicabilité conduit à la compréhension de ces mêmes résultats.
Pour la bonne interprétabilité d’un système d’IA, une explication spécifique doit être apportée à chaque groupe de personnes interagissant avec celui-ci afin de permettre la bonne compréhension des résultats par chacun d’entre eux. Par exemple, pour un même système :
- Le concepteur de l’IA aura besoin d’informations particulières concernant les erreurs constatées lors de l’ajustement des paramètres ou du jeu de données d’apprentissage ;
- L’utilisateur final de l’IA devra comprendre comment l’IA a pris sa décision dans son cas particulier ;
- Une autorité de certification demandera de comprendre la logique de fonctionnement générale de l’IA.
L’interprétabilité du système d’IA conduit à son explicabilité
Ici, la première lecture de l’interprétabilité consiste à considérer que si un élément d’un système d’IA, comme un résultat ou un comportement peut être associé à un modèle mental par une représentation particulière, alors il est possible d’expliciter les facteurs importants qui influencent les résultats du système. L’exemple contraire extrême serait un ensemble de décision prises par un modèle purement stochastique ; aucun schéma mental ne peut y être associé. On est alors en présence d’un processus ininterprétable et donc des décisions et un modèle inexplicables. L’interprétabilité du système d’IA est donc bien un prérequis à son explicabilité. Si on s’arrête là, les notions d’explicabilité et d’interprétabilité sont insuffisantes et des questions se posent alors du fait du manque d’un élément rattachant les résultats d’explicabilité au modèle mental : Comment déterminer la logique sous-jacente de l’IA ? Comment doit-on la présenter à l’être humain ? Qu’est-ce qu’une bonne explication ? Dans la littérature scientifique, il n’existe pas de consensus pour répondre à ces questions. C’est la raison pour laquelle on retrouve une grande variété de travaux proposant des approches différentes non opposables les unes aux autres et souvent complémentaires.
Voici quelques-unes de ces approches, illustrées par un exemple d’une IA prédisant le salaire d’une personne à partir de son CV :
- Objectif de l’approche de la simplification de l’IA : construction de règles facilement compréhensibles par un être humain schématisant le fonctionnement de l’IA.
Illustration : Si le nombre d’années d’expérience est supérieure à 5 ans et que la personne a un bac+3 alors son salaire sera de X euros. - Objectif de l’approche sur l’importance des entrées : déterminer quelles variables ont le plus d’influence dans la prise de décision de l’IA.
Illustration : Le nombre d’années d’expérience d’une personne est un des facteurs les plus influents dans la détermination de son salaire. - Objectif de l’approche sur des explications : pour une décision particulière, on recherche un ensemble d’exemples similaires qui sont traités de la même manière par l’IA.
Illustration : pour un CV donné, on essaye de trouver un ensemble des CV similaires qui conduisent à la même prédiction de salaire. - Objectif de l’approche sur l’IA fournissant une explication : l’IA peut elle-même prédire une explication par exemple sous la forme de texte.
Illustration : J’ai déterminé le salaire de X euros car l’expérience et l’expertise de cette personne sont rares sur le marché. - Objectif de l’approche où, par sa structure, l’IA fournit des éléments d’explicabilité : des composants internes du modèle caractérisent un groupe d’individus.
Illustration : A partir d’un CV, l’IA calcule un élément caractérisant la rareté du profil sur le marché. Cette caractéristique est ensuite utilisée par l’IA pour calculer le salaire.
Le projet DEEL a référencé l’ensemble des techniques que nous pouvons trouver dans la littérature et travaille suivant deux axes :
- Les métriques d’explicabilité dont l’objectif est d’essayer de répondre aux questions suivantes :
- Qu’est-ce qu’une bonne explication ?
- Quelles propriétés doit avoir une bonne explication ?
Pourtant critique, ce champ de recherche est très peu exploré dans la littérature pour permettre d’avoir confiance en l’explication que l’on fournit à l’utilisateur. Sans une mesure de l’explication, il n’est pas possible de comparer si une méthode est meilleure qu’une autre et donc aucune garantie ne peut être fournie sur ces explications.
Les méthodes formelles pour l’explicabilité permettant de pallier le fait que de nombreuses techniques d’explicabilité peuvent être trompées par des techniques d’attaques adverses. Pour ces techniques, une faible altération de l’entrée fournie au modèle peut induire une explication complètement différente alors que l’IA ne semble pas changer sa prédiction, tout comme elle peut induire une même explication alors que l’IA a changé complètement sa prédiction. Ces comportements ne sont pas acceptables car l’utilisateur peut mettre en doute la fiabilité de cette explication ou être dupé par celle-ci. Des techniques apportant certaines garanties théoriques sur les explications fournies aux utilisateurs sont explorées.
L’interprétabilité appliquée aux représentations produites par l’explicabilité
La seconde lecture de l’interprétabilité consiste à considérer que l’interprétabilité est appliquée aux représentations produites par les méthodes d’explicabilité. Il s’agira de comprendre les résultats de ces méthodes en ajoutant des éléments endogènes du système (structure, inférence etc.) ou exogènes (ODD : Operational Domain Design, profil utilisateur, etc.)
L’illustration ci-dessous montre les résultats d’une même méthode d’explicabilité appliquée à la qualification de cordons de soudure sur une chaîne de production avec deux qualifications possibles : « ok » ou « à retoucher ». Le modèle de classification a été appliqué sur ces deux images et la méthode d’explication montre quelles sont les zones influentes de l’image induisant la décision prise. Ces deux « explications » sont pertinentes et justes. Toutefois elles sont complètement dissemblables, l’une indiquant un point chaud, rouge, sur la soudure et l’autre, un froid, bleu. Il y a incompréhension des résultats d’explication proposés.
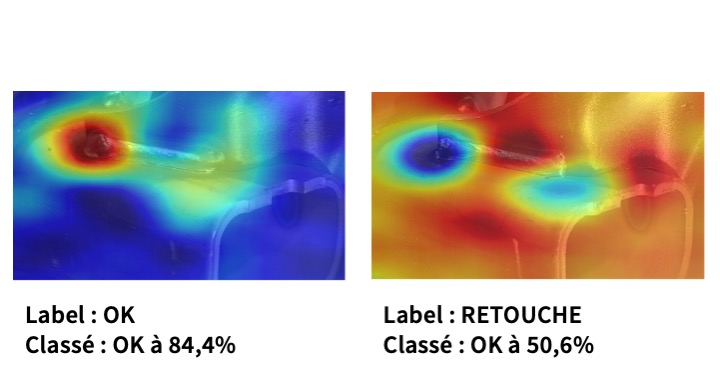
Figure 1 : Carte de chaleur issues de la méthode d’explicabilité RISE de la bibliothèque Xplique (DEEL)
Nous voyons bien que sans élément supplémentaire porté à la connaissance de l’utilisateur, ici le concepteur du système d’IA, il semble que la méthode d’explication, le modèle ou les deux ne sont pas de confiance. La prise en compte du fait que le modèle a mal classé l’image de droite vient changer la visualisation mentale du processus : l’explication montre l’erreur du modèle. La prise en compte de tous ces éléments liés à l’environnement de la prise de décision ou du domaine d’application nous donne des clés pour répondre au problème de l’explication spécifique, dédiée à un groupe de personnes, dans un domaine de compétence et de connaissance spécifique. En bref, à un profil utilisateur.
Cette notion n’a pour le moment pas de terme explicite dans le programme ; et « l’interprétabilité » fait fonction. Jusqu’à présent, nous ne nous y sommes pas confrontés car occupés à élaborer et intégrer un puissant ensemble d’outils d’explicabilité applicables à chaque cas d’usage. C’est donc une des directions des travaux qui vont être menés cette année dans le projet deux “Process, methodologies and guidelines” de Confiance.ai, incluant toutes les briques logicielles développées autour des méthodes et métriques d’explicabilité, des mesures d’incertitude, de la détection de l’OOD (Out Of Distribution), des scores de confiance, de la robustesse des modèles etc. : comment tout ça peut s’articuler pour fournir un niveau de compréhension et de confiance accru ? Nous avons maintenant à intégrer les profils utilisateurs et les domaines d’utilisation dans la chaîne d’interprétabilité et d’explicabilité pour que les systèmes d’intelligence artificielle soient compris et acceptés.
Un article rédigé par Philippe Dejean, co-leader du projet « Caractérisation et qualification d’une IA de confiance ».